Udify¶
Overview¶
Udify is a BERT based, multilingual multi-task model capable of predicting universal part-of-speech, morphological features, lemmas, and dependency trees simultaneously for 75 languages.
Installation¶
Download the model from release page
Install with pip:
$ pip install en_udify-0.6.0.tar.gz
All parameters and dependencies are installed now.
Usage¶
>>> import spacy >>> nlp = spacy.load("en_udify") >>> doc = nlp("Udify is a BERT based dependency parser") >>> spacy.displacy.render(doc)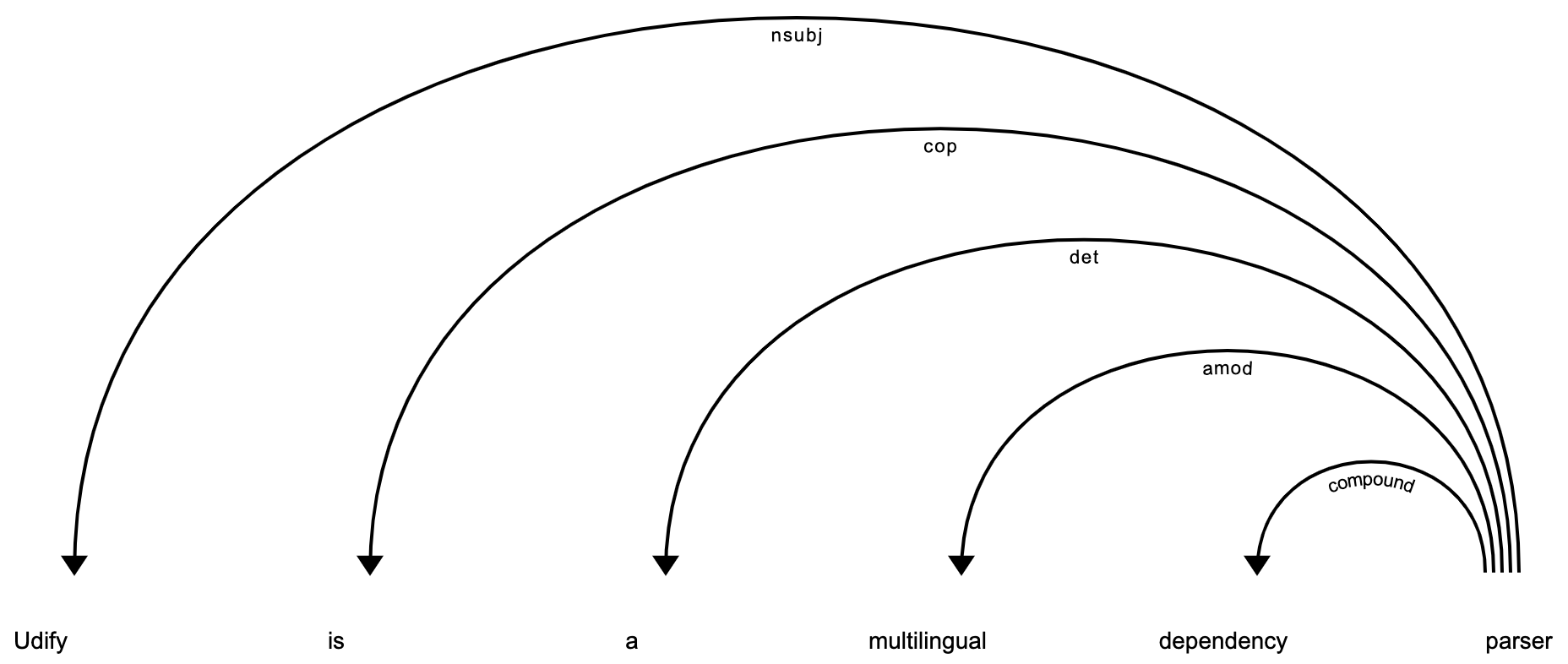
Now you can use nlp for space-delimited languages such as English and German:
>>> doc = nlp("Deutsch kann so wie es ist analysiert werden") >>> spacy.displacy.render(doc)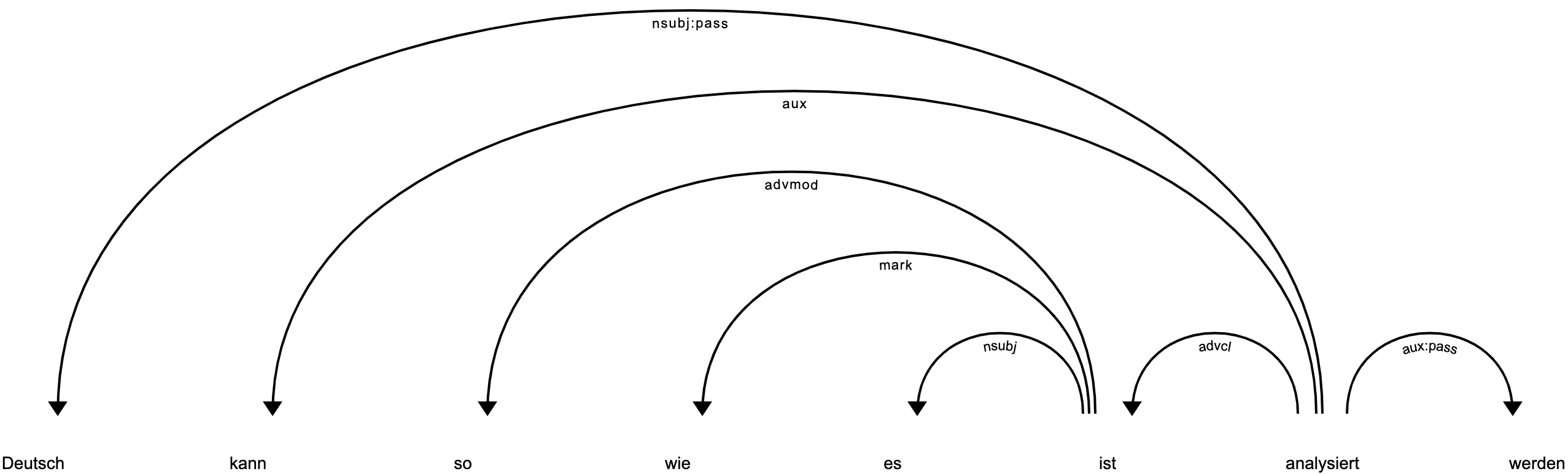
Use udify with non-space-delimited languages¶
Switching the tokenizer allows you to use Udify for non-space-delimited languages such as Japanese.
Camphr offers a useful function for this purpose: load_udify:
>>> from camphr_allennlp.udify import load_udify >>> nlp = load_udify("ja", punct_chars=["。"]) >>> doc = nlp("日本語も解析可能です") >>> spacy.displacy.render(doc)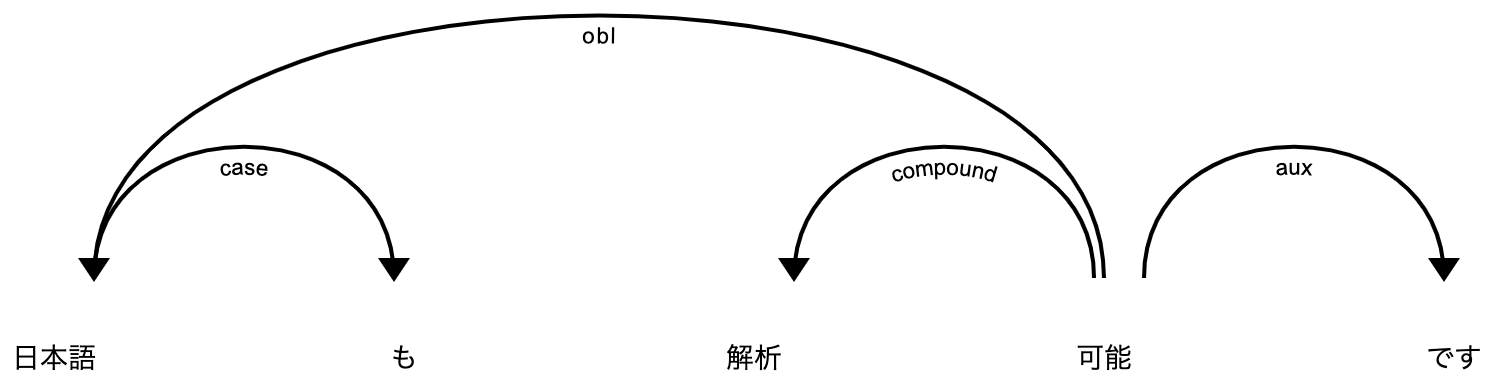
Note
To use Udify with Japanese, mecab-python3 is required. Install with pip install mecab-python3
